Data
The shared tasks corpora are composed of articles sampled among several Swiss, Luxembourgish and American historical newspapers on a diachronic basis.
Data acquisition and format are described in the HIPE - Shared Task Participation Guidelines.
Data sets:
- Sample data for French and German is available HERE. It consists of 10 French and 8 German content items fully annotated.
- Training and dev data sets (all versions) are available HERE. See statistics below.
Auxiliary resources
HIPE provides several ‘in domain’ embeddings acquired from the impresso newspapers and time periods from which HIPE training and development sets were extracted.
We strongly encourage participants to also share any external resource they might use, during and/or after the evaluation campaign.
- fasttext word embeddings
We offer fasttext word embeddings without subwords (link) and with subword 3-6 character n-grams (link). Additionally to the binary models, we uploaded textual .vec formats. For all downloads, follow this link.
The preprocessing tries to mimic the tokenization of the HIPE data and involves the following normalizations: lowercasing; replacement of each digit by 0; deletion of all tokens with length 1 (e.g. punctuation).
The exact training parameters of each model MODEL.bin can be found in the corresponding file MODEL.bin.info.txt as computed by the fasttext dump args.
For more information on fasttext and tutorials, visit the fasttext website.
- flair contextualized string embeddings (aka. character embeddings)
For download, visit this link. You will find the forward and backward model for each language in a separate directory: best-lm.pt contains the parameters you will use and loss.txt contains the training logs (scores on the training and dev set).
The preprocessing involves the following steps: lowercasing; replacement of each digit by 0; replacement of each newline by space. Everything else was kept as in the original text (e.g. tokens of length 1).
Here is an example of the input to flair:
in . the mer- chant's, family was lost sight of. it was doubtless destroyed more than a cen- tury ago. liut not so with tatty, the pet of the parsonage. abigail french, the minis- ter's daughter, w
as born on the last day of may, 0000. she was eight years of age when she received this treasure. mrs`
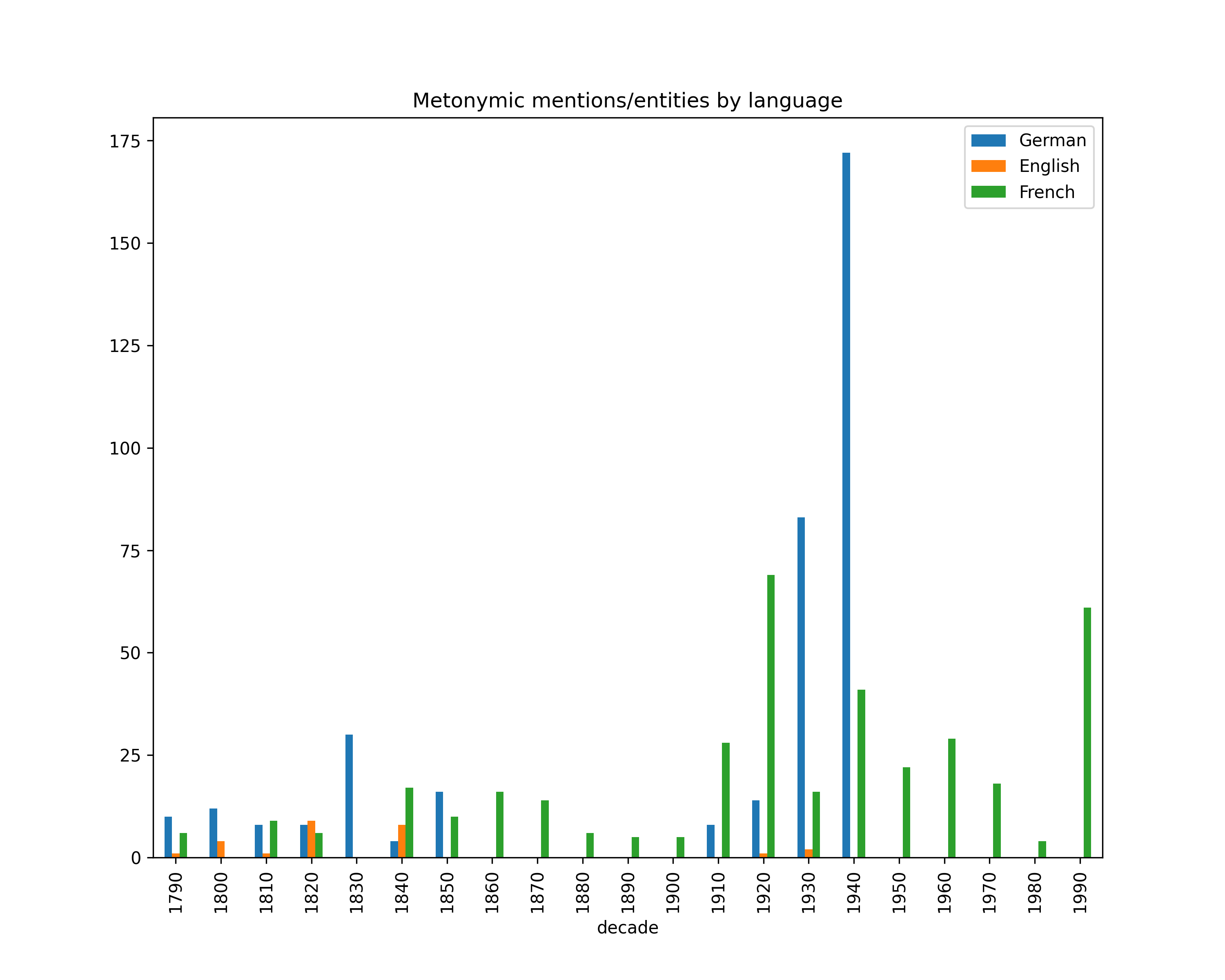
The amount for our our in-domain training differs largely between languages: French taken from Swiss and Luxembourgish newspapers: 20G; English taken from Chronicling America material: 1.1G; German taken from Swiss and Luxembourgish newspapers: 8.5G.
The embedding size for characters is 2048. We use flair 0.4.5 to compute the embeddings using a context of 250 characters, a batchsize of 400-600 (depending on the GPUs memory), 1 hidden layer, dropout of 0.1. See the tutorial on language modeling for more information.
For more information on flair and tutorials on how to use flair embeddings, visit the flair website.
We strongly encourage participants to also share any external resource they might use, during and/or after the evaluation campaign.
Statistics about HIPE data release v1.2
Computed on version v1.02 of our datasets; last update: 12 May 2020.
Overview
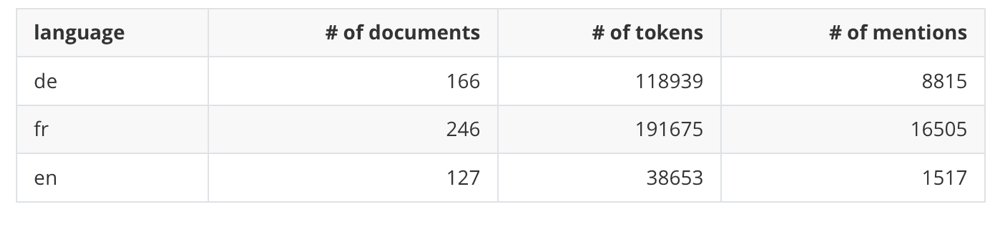
As a reminder, we are not releasing training data for English.
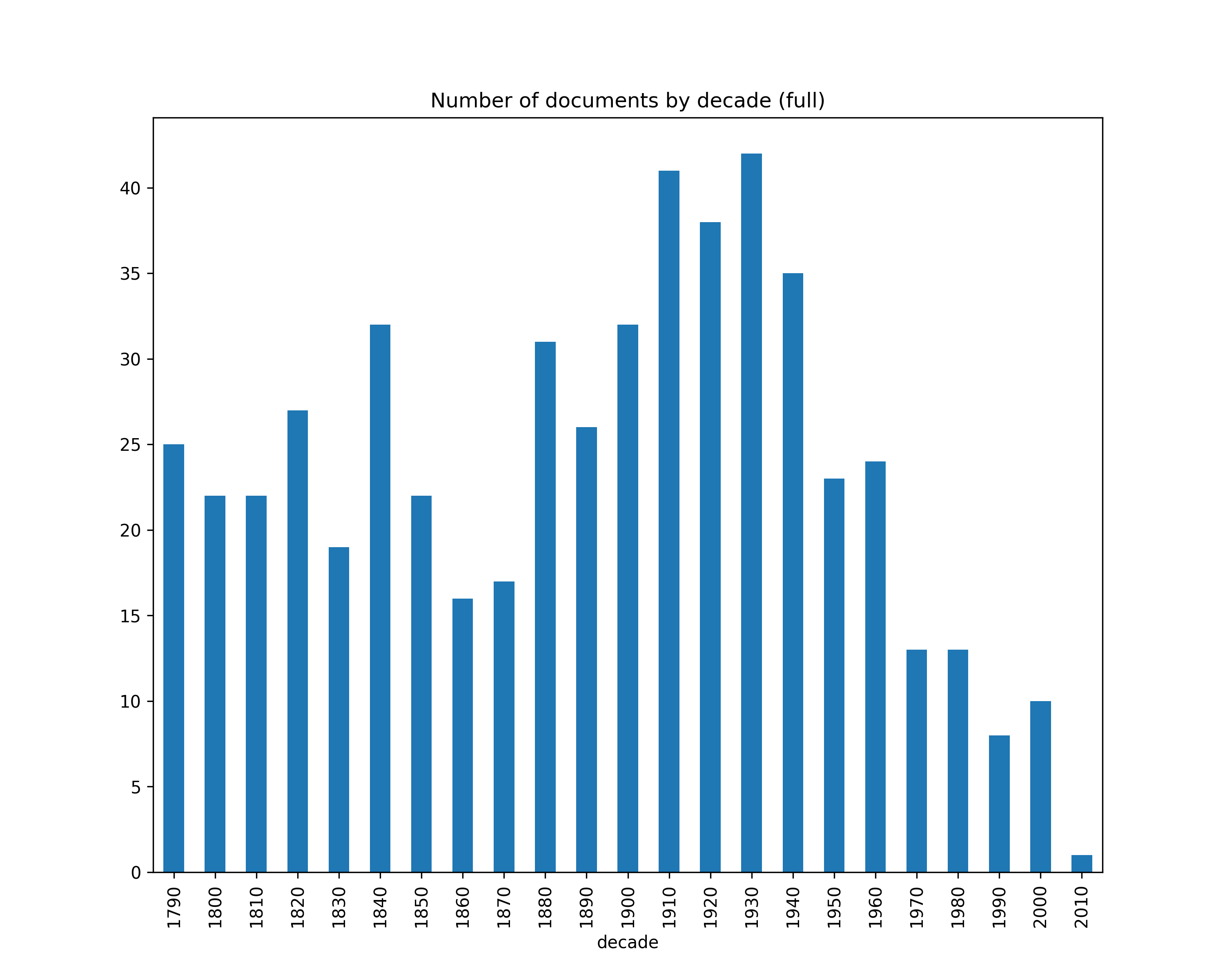
Number of documents by decade
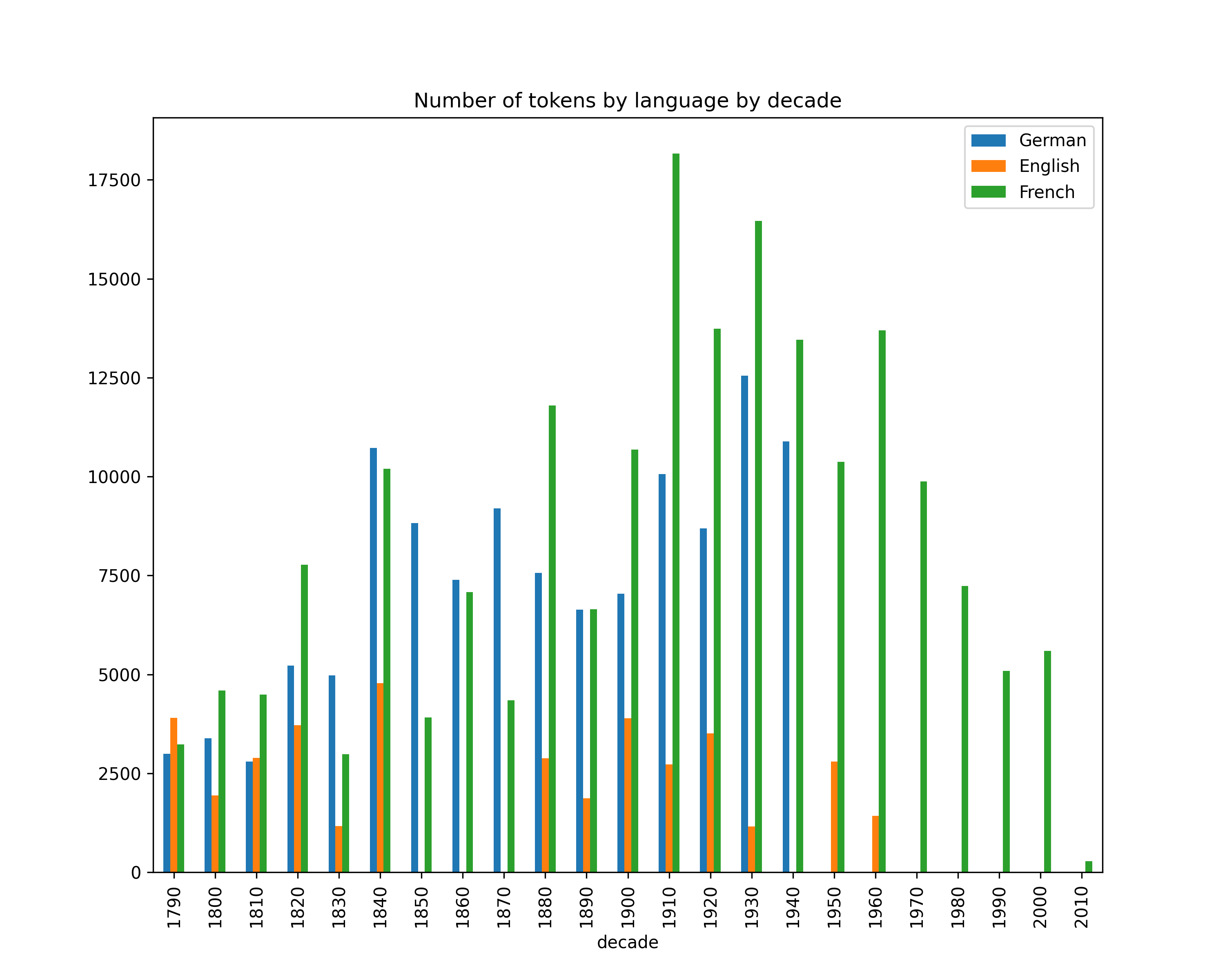
Number of tokens by decade
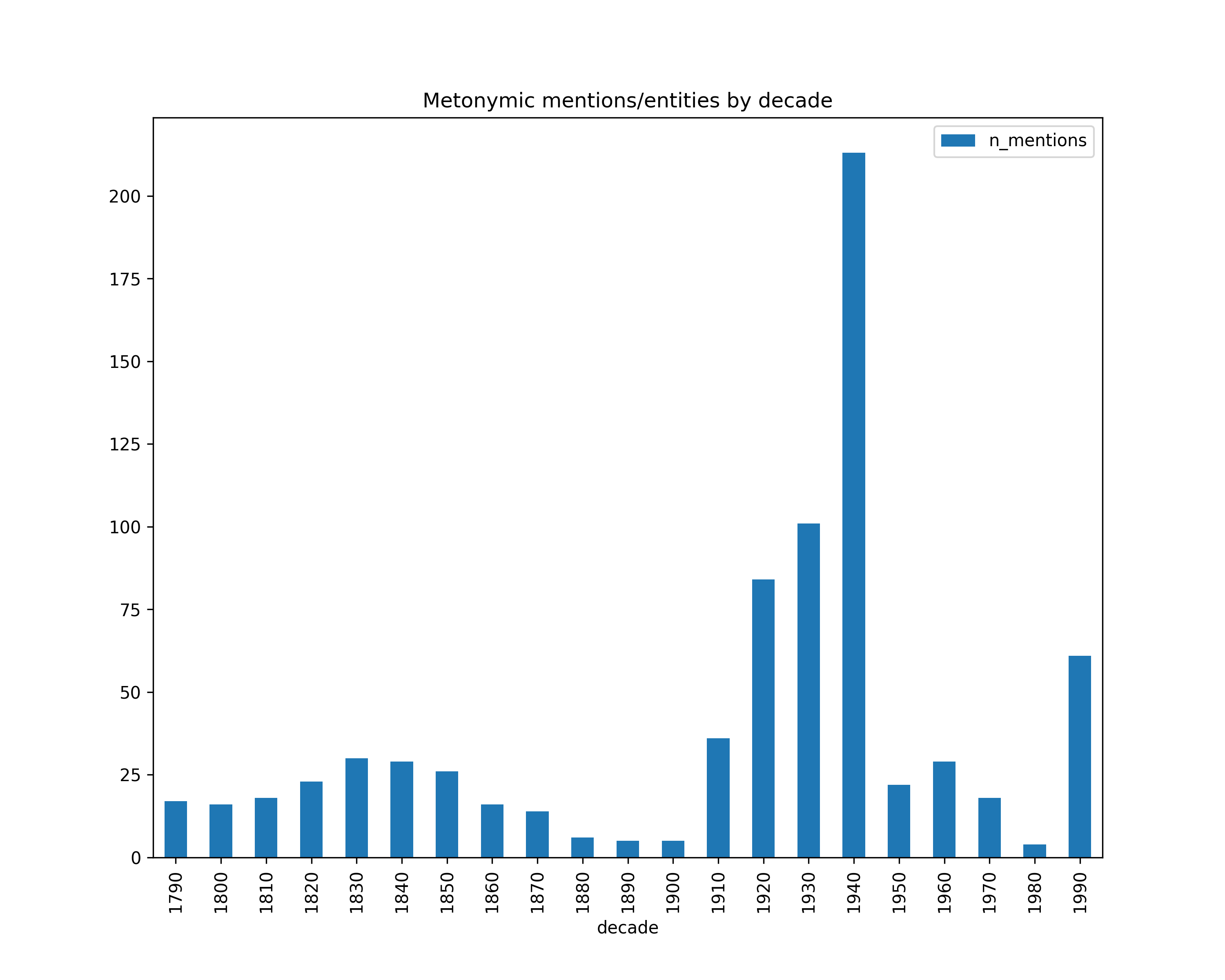
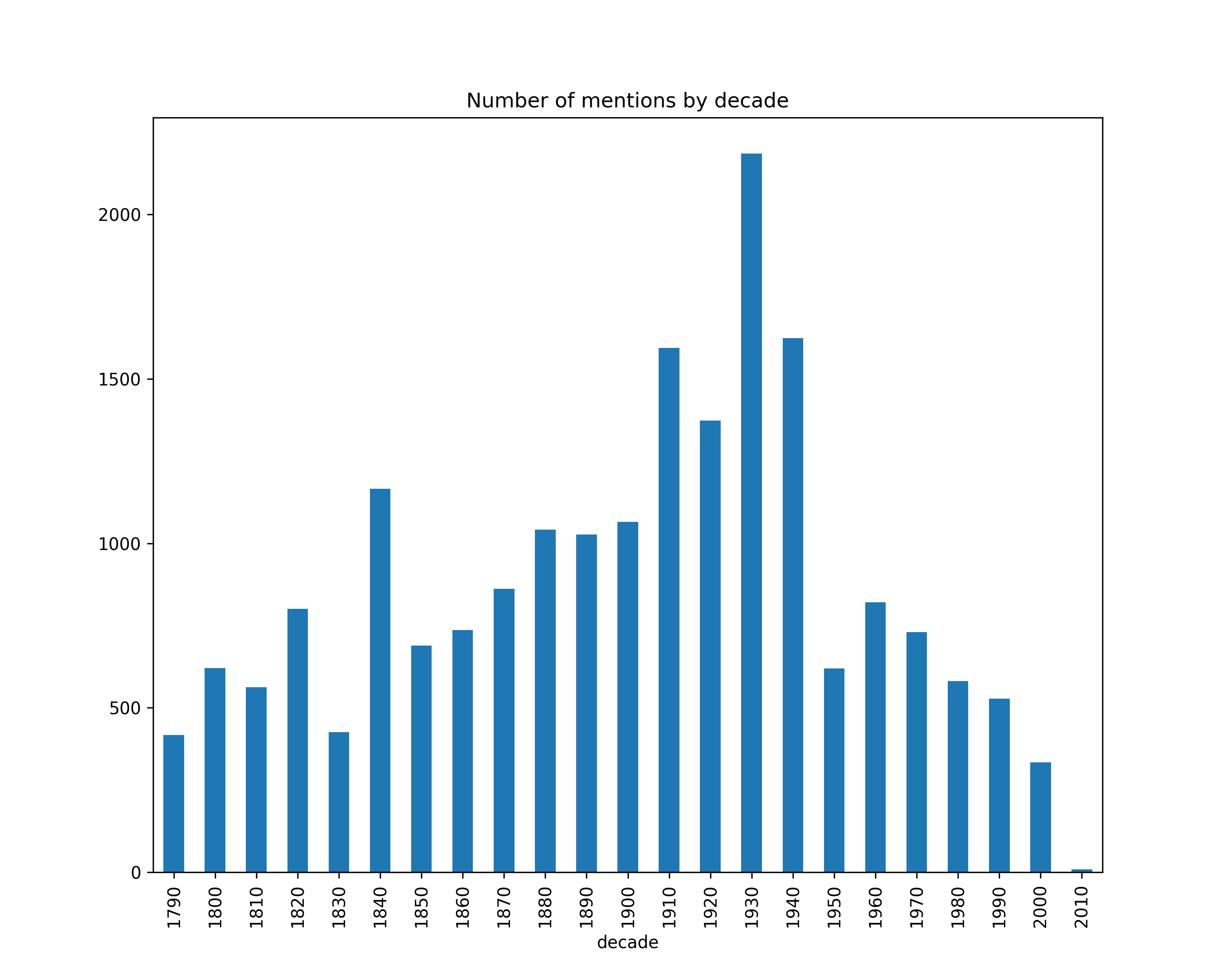
Number of mentions by decade
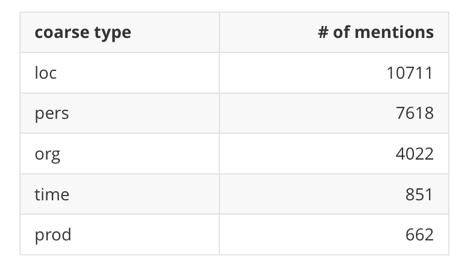
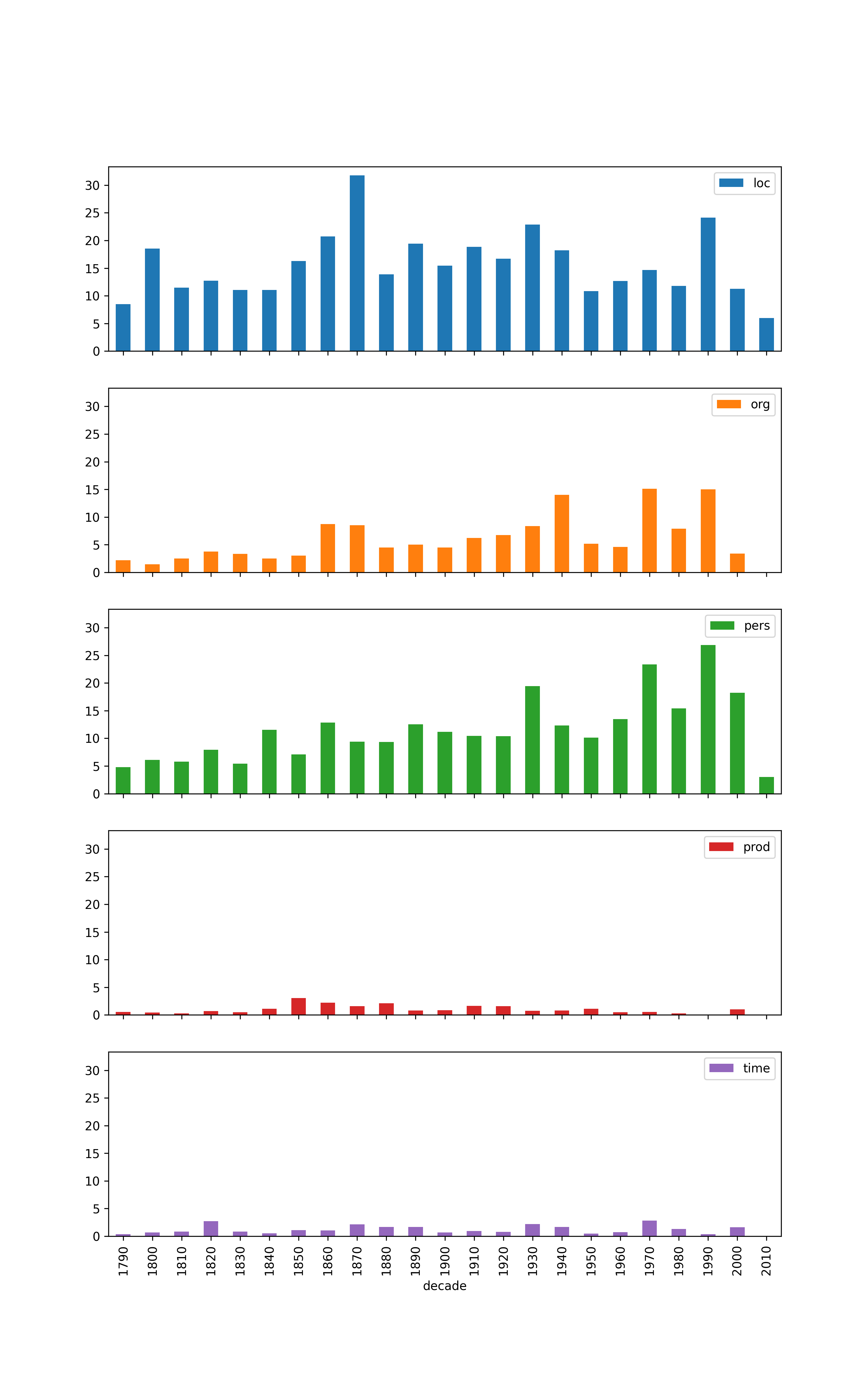
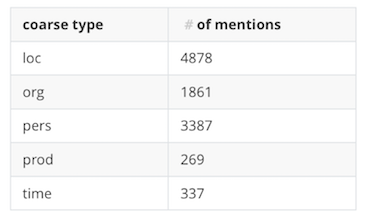
Number of mentions, broken down by type (coarse)
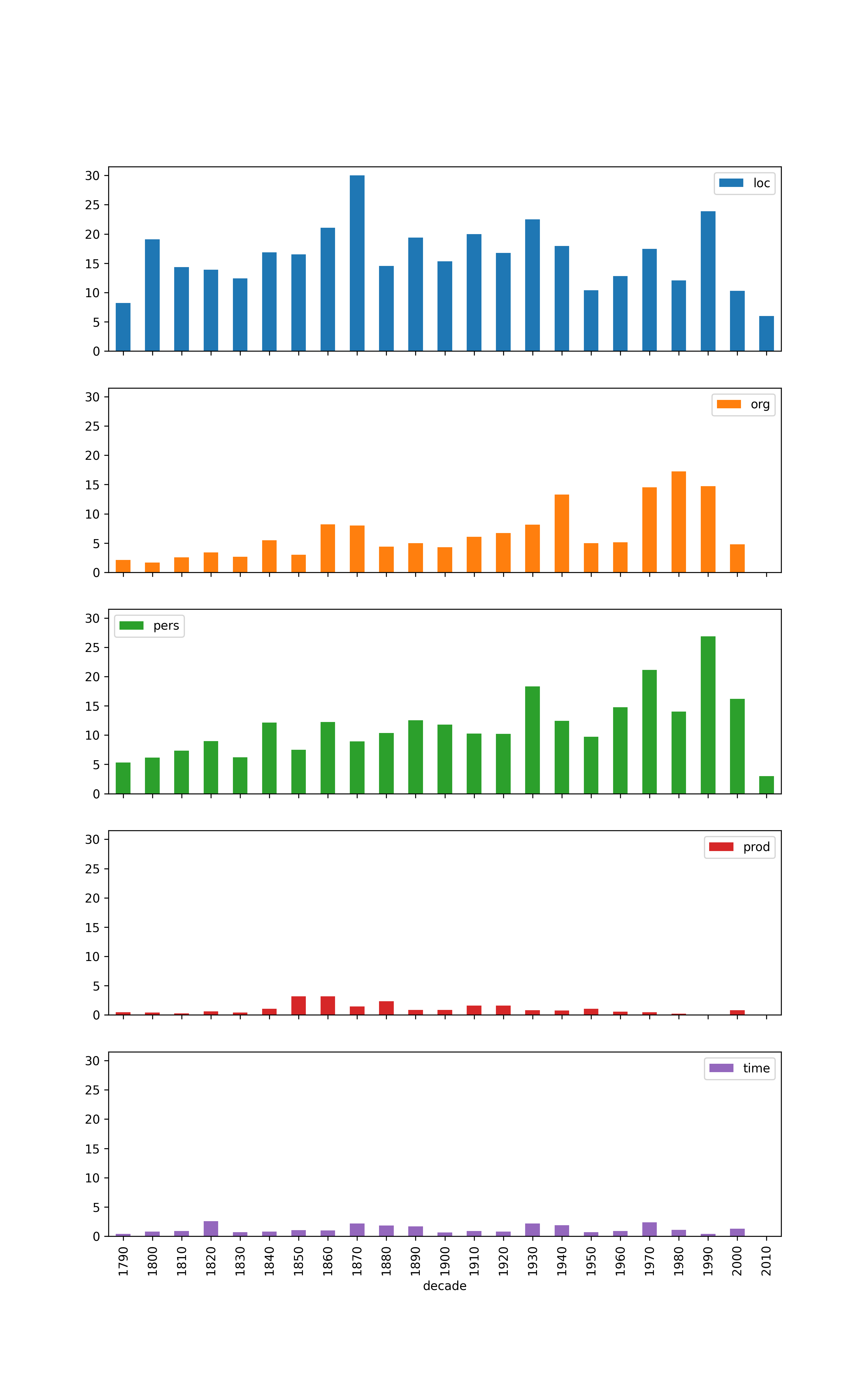
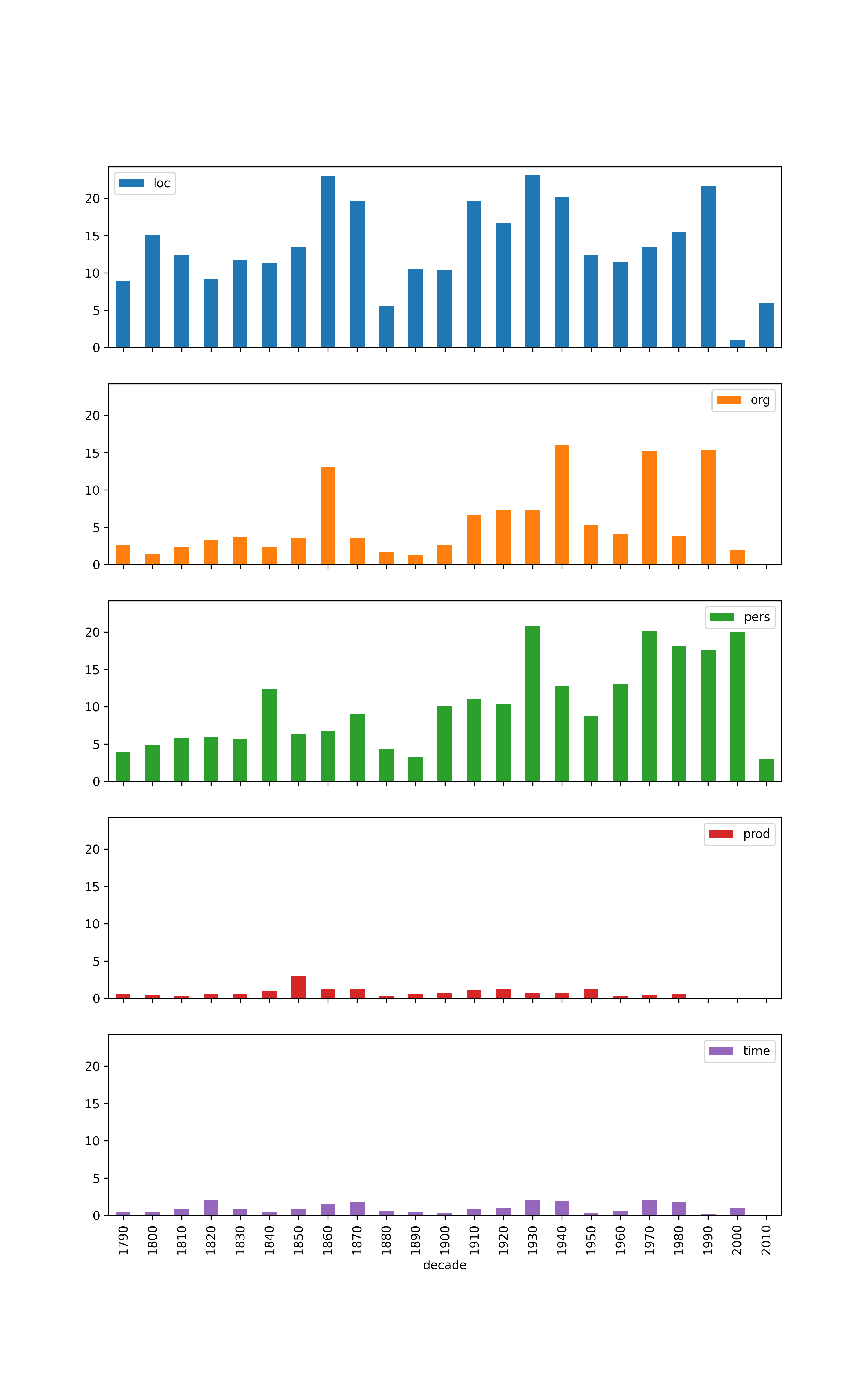
Number of mentions by decade, broken down by type (coarse)
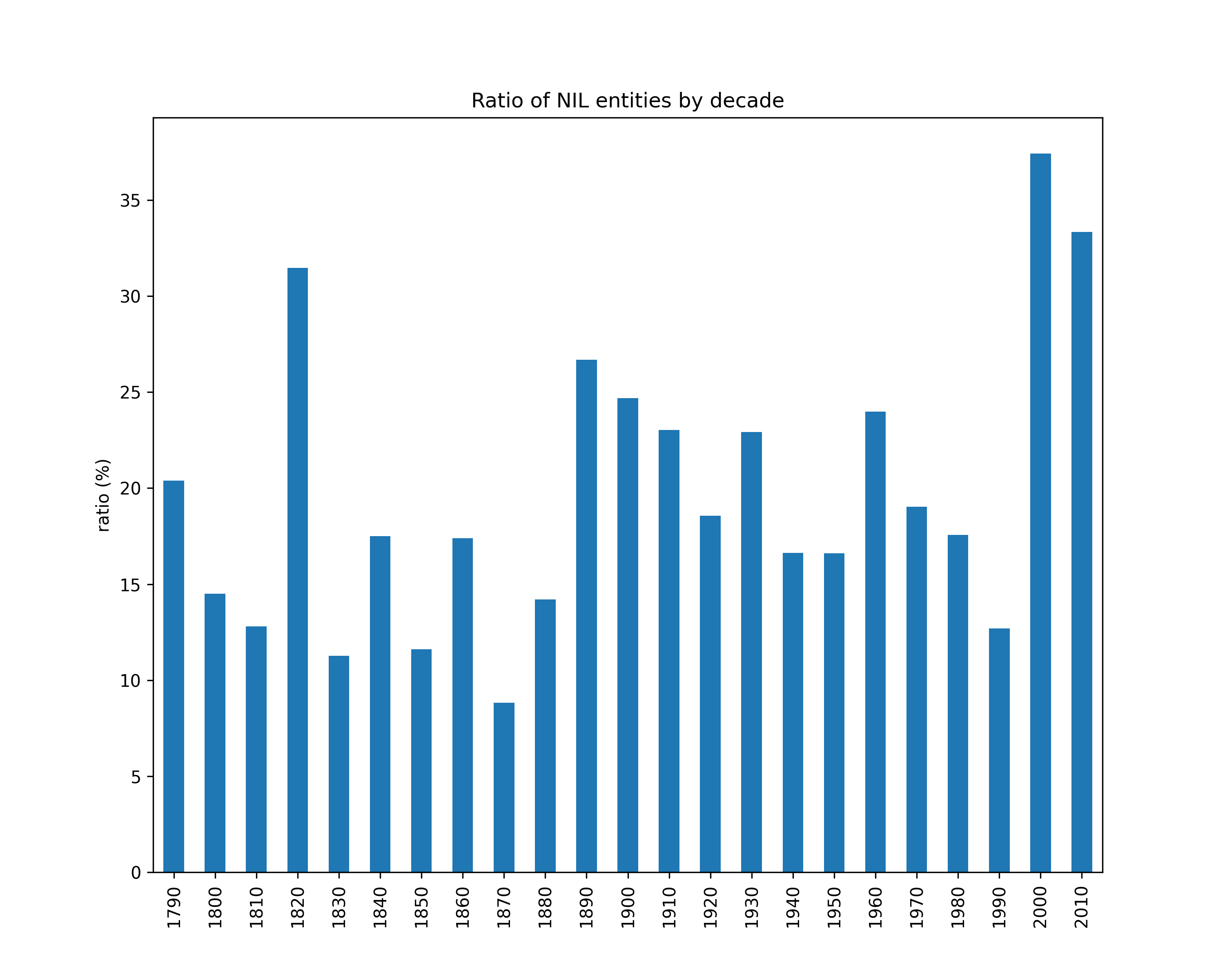
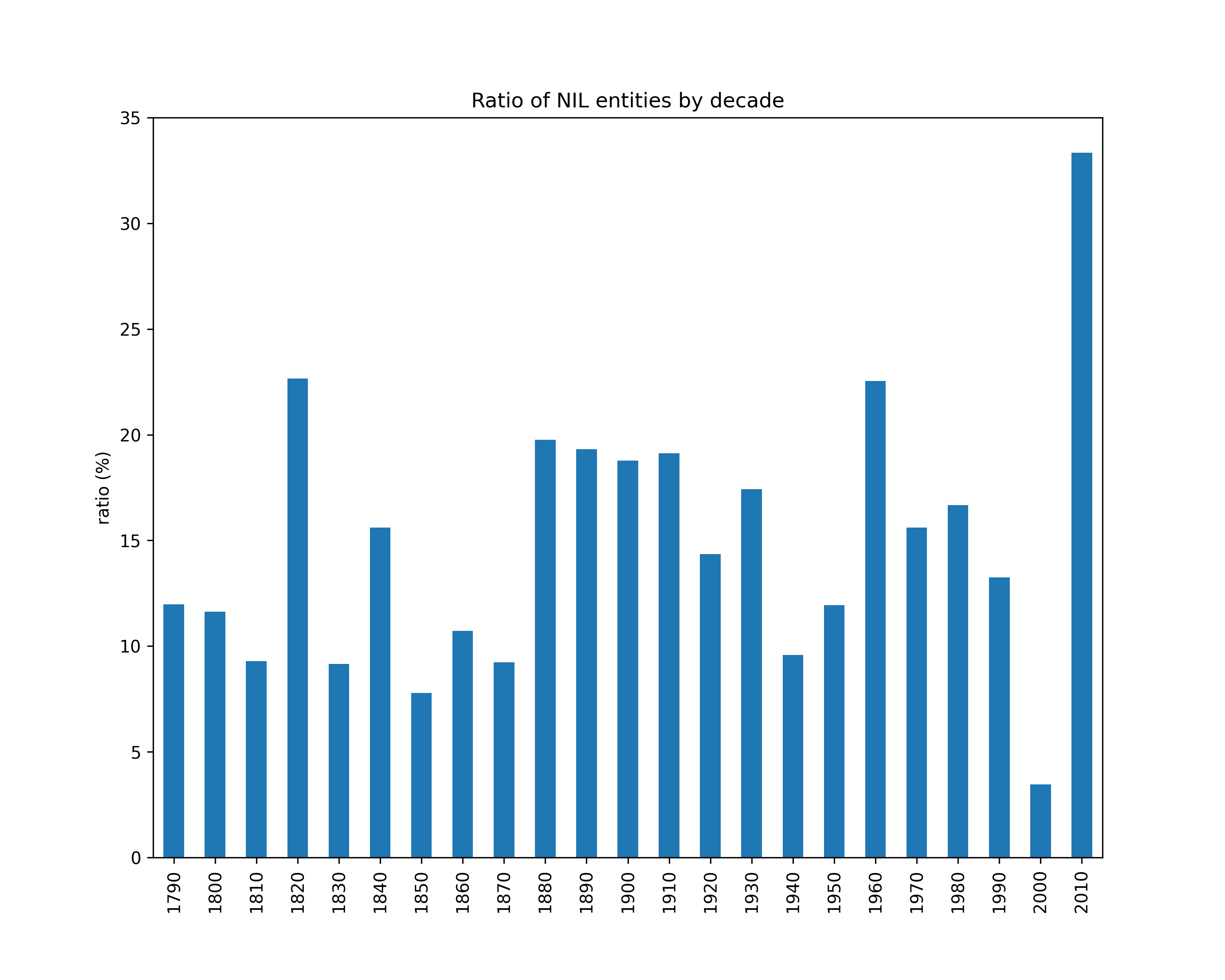
NIL entities ratio
Number of NIL entities over the total number of mentions (per decade).
NIL entities by mention type (coarse)

Metonymy
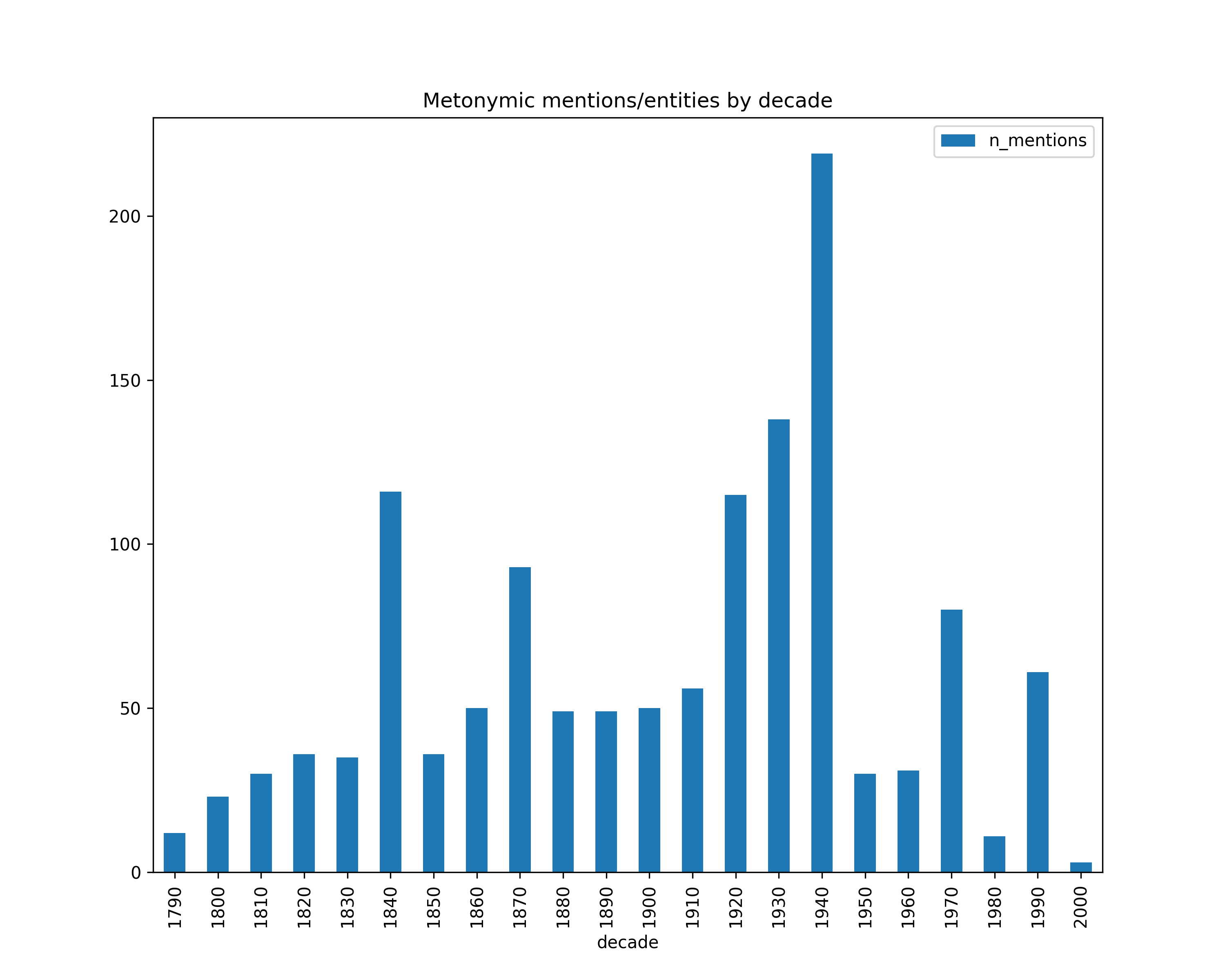
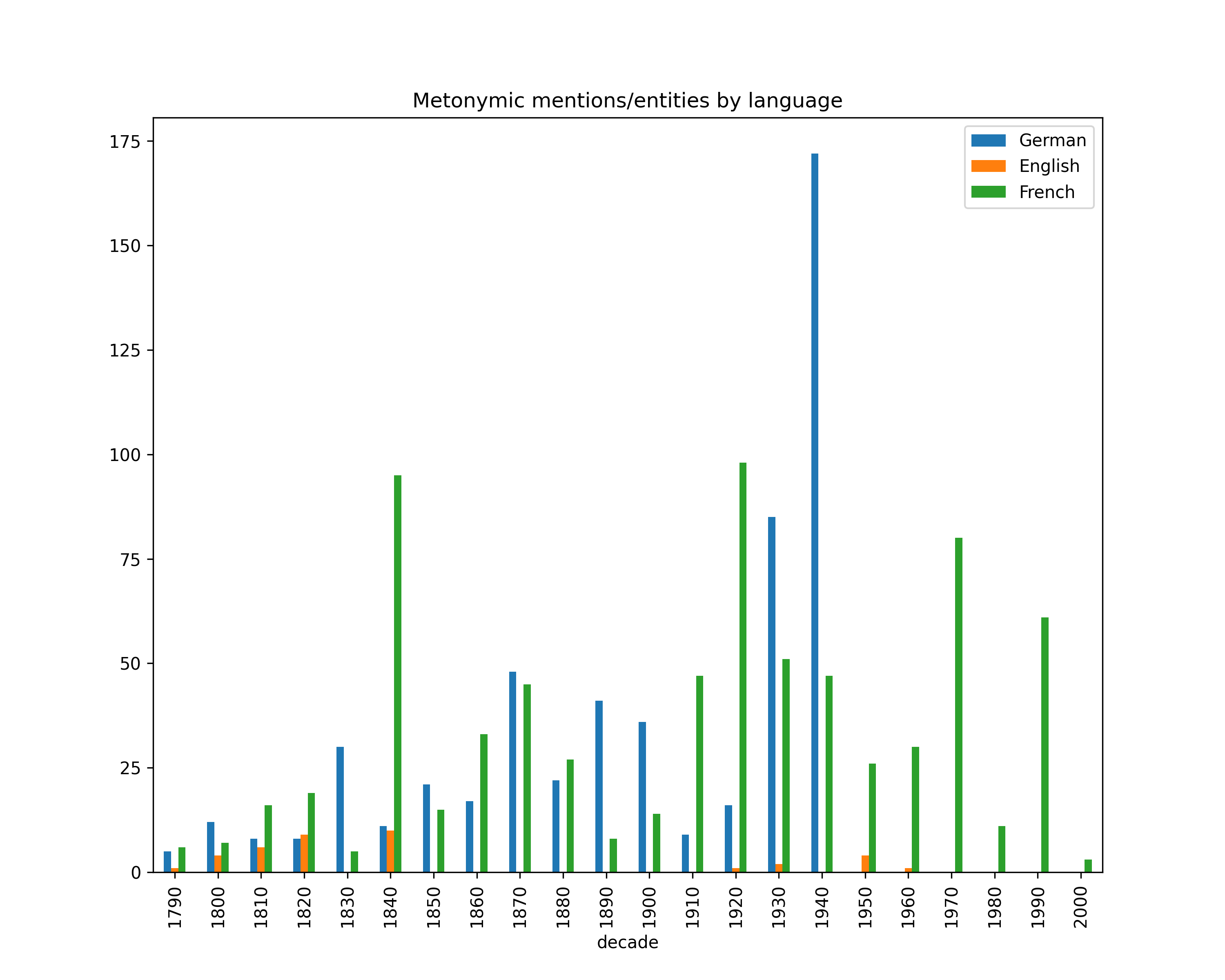
Statistics about HIPE data release v1.1
No statistics, data very similar to v1.0
Statistics about HIPE data release v1.0
Computed on version v1.0 of our datasets; last update: 26 March 2020.
Overview
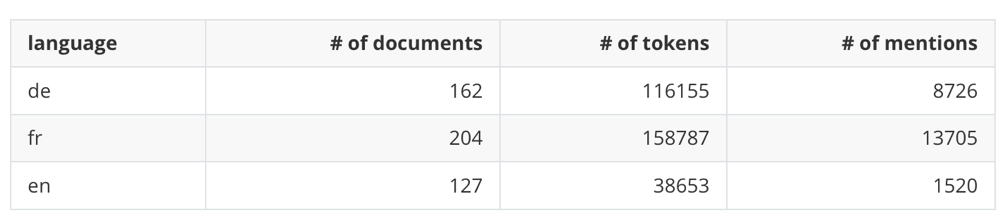
As a reminder, we are not releasing training data for English.
Number of documents by decade
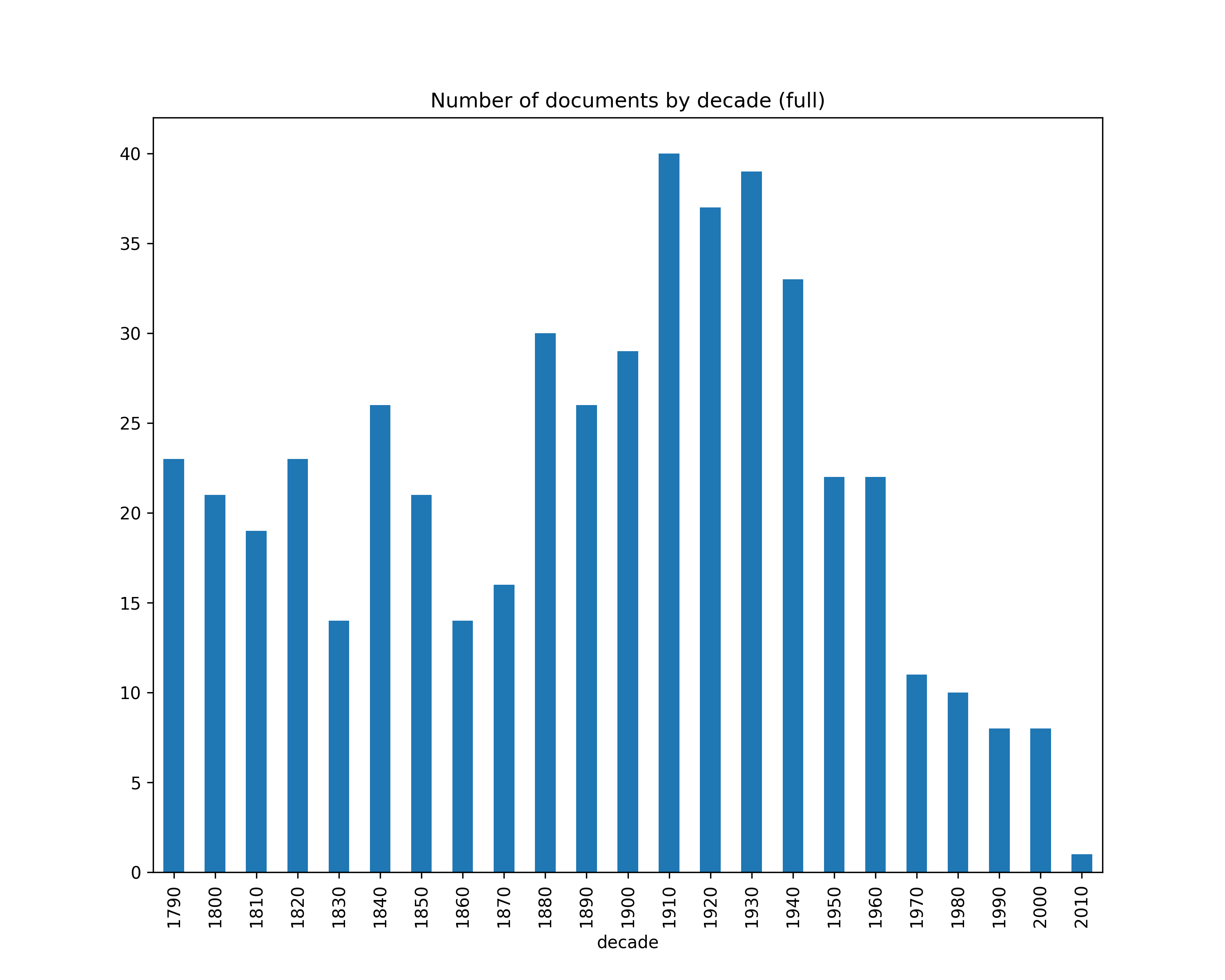
Number of tokens by decade
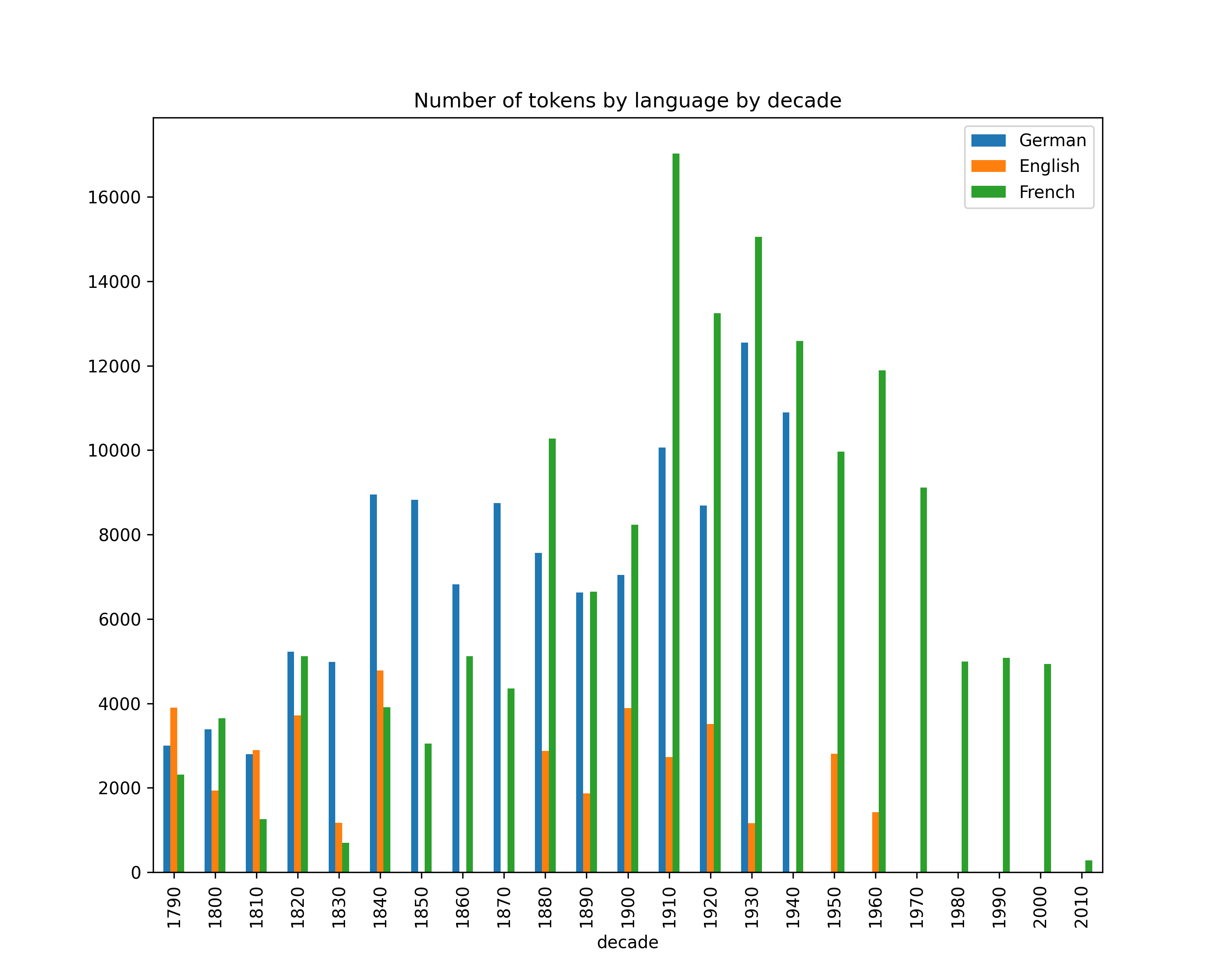
Number of mentions by decade
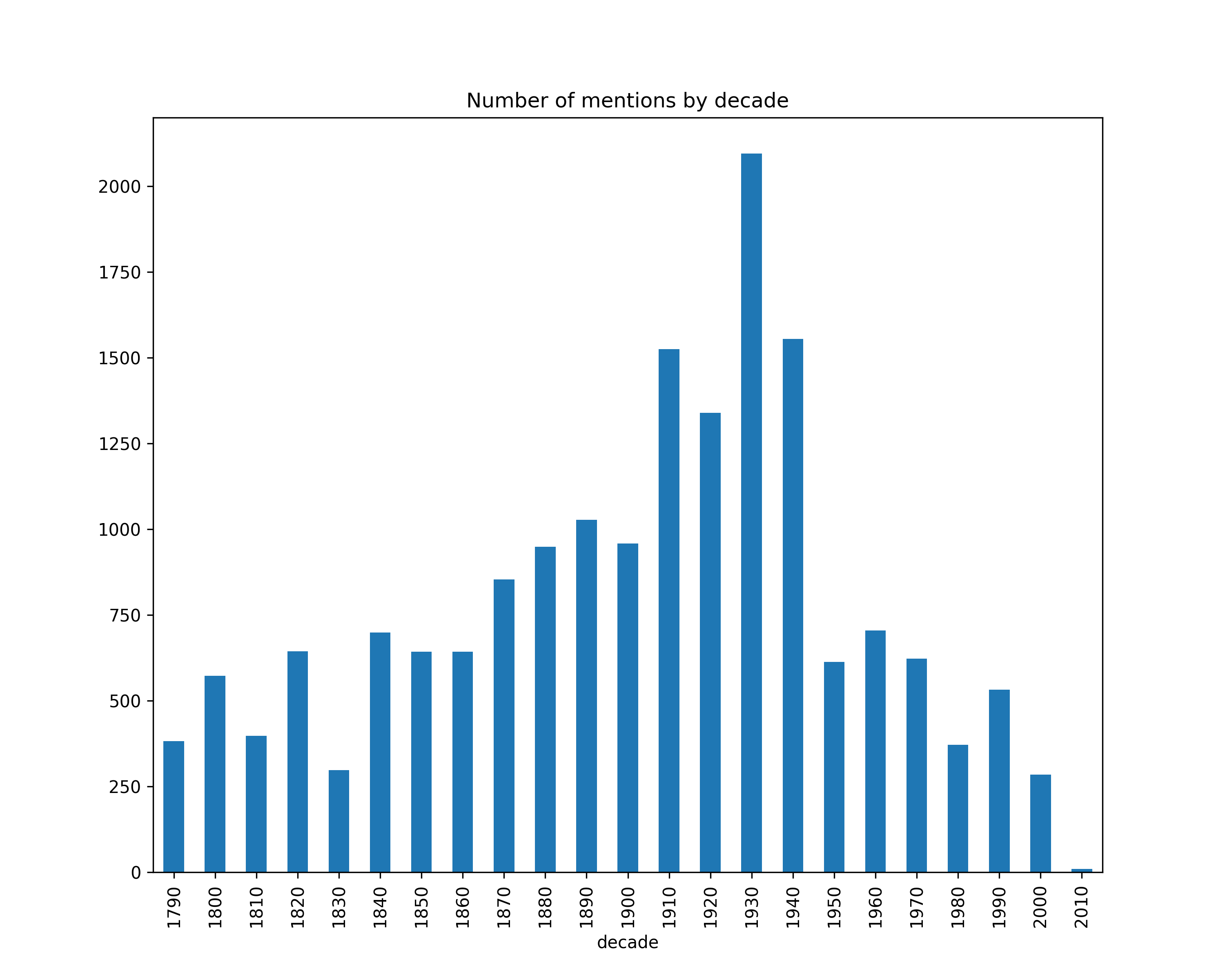
Number of mentions, broken down by type (coarse)
Number of mentions by decade, broken down by type (coarse)
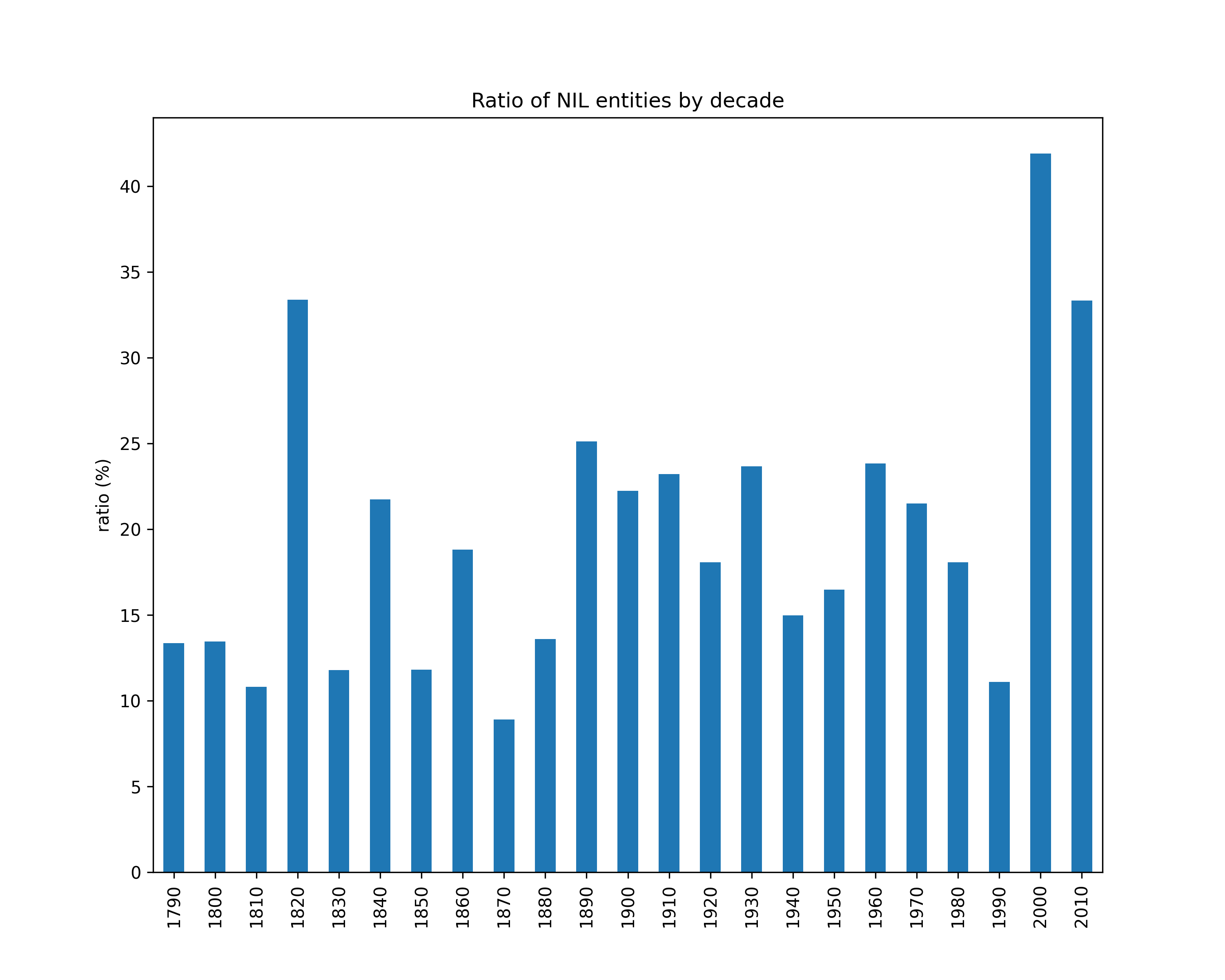
NIL entities ratio
Number of NIL entities over the total number of mentions (per decade).
NIL entities by mention type (coarse)

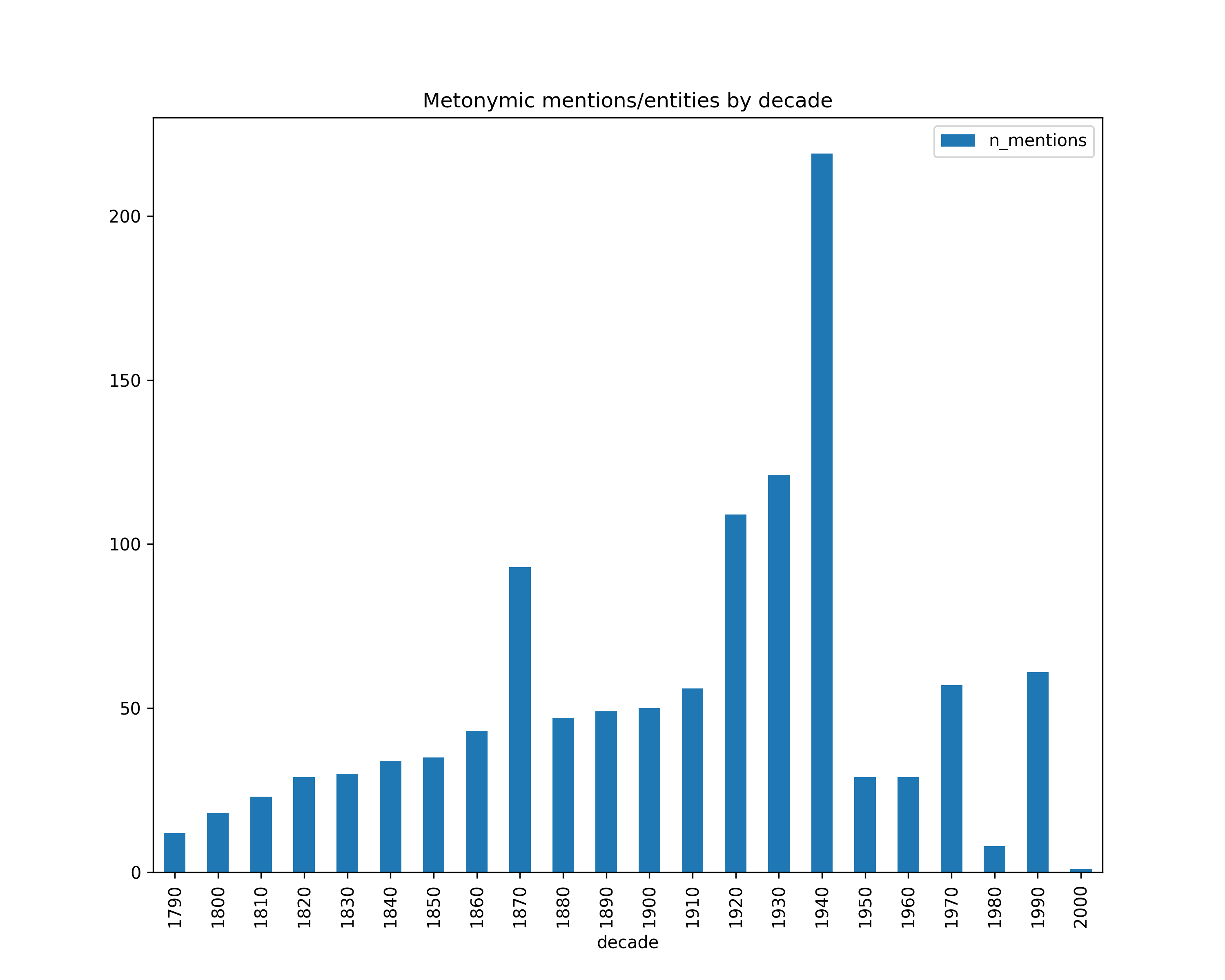
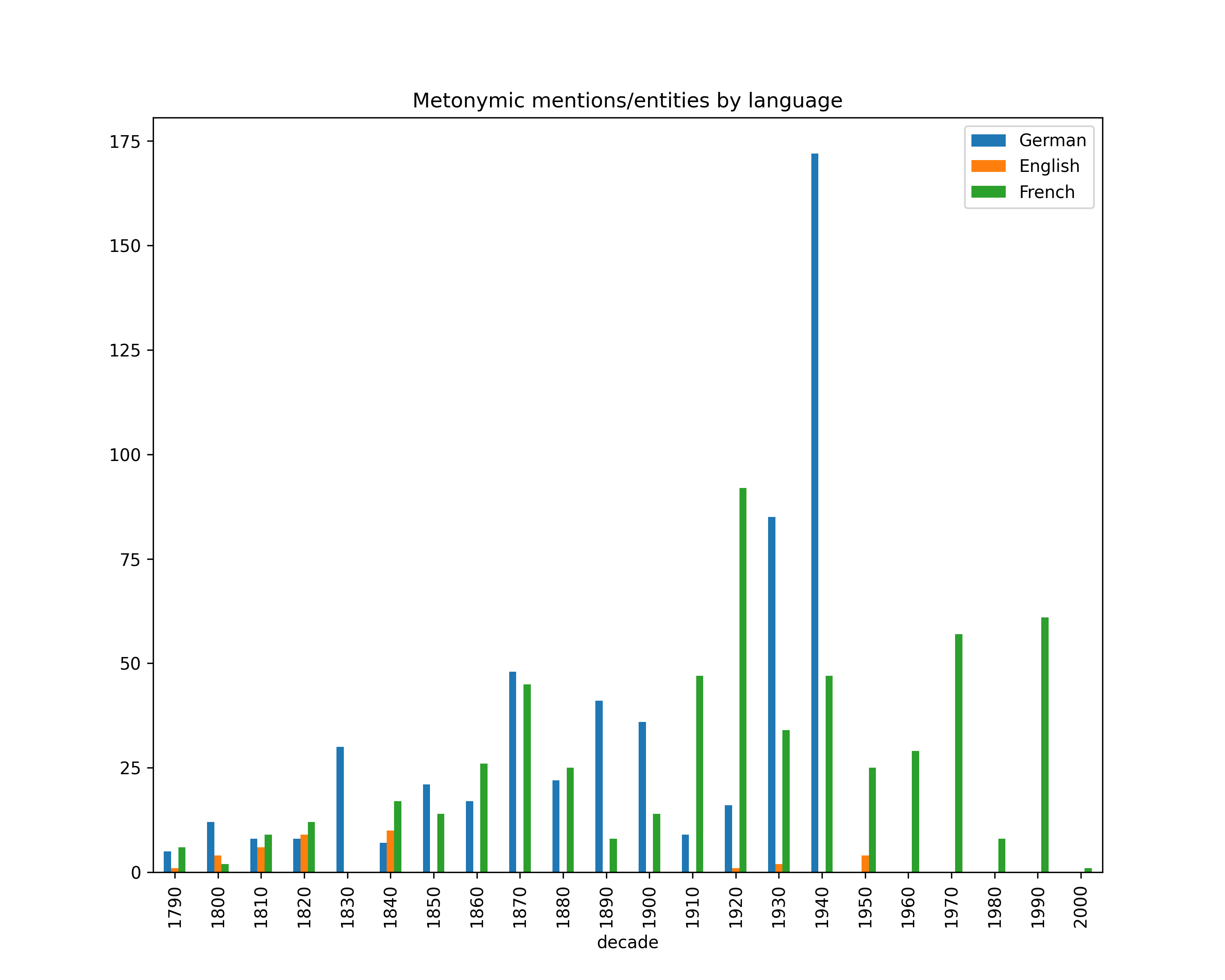
Metonymy
Statistics about HIPE data release v0.9
Computed on version v0.9 of our datasets; last update: 20 February 2020.
Overview
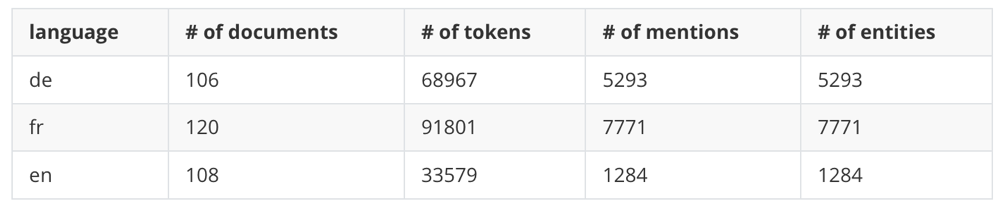
As a reminder, we are not releasing training data for English.
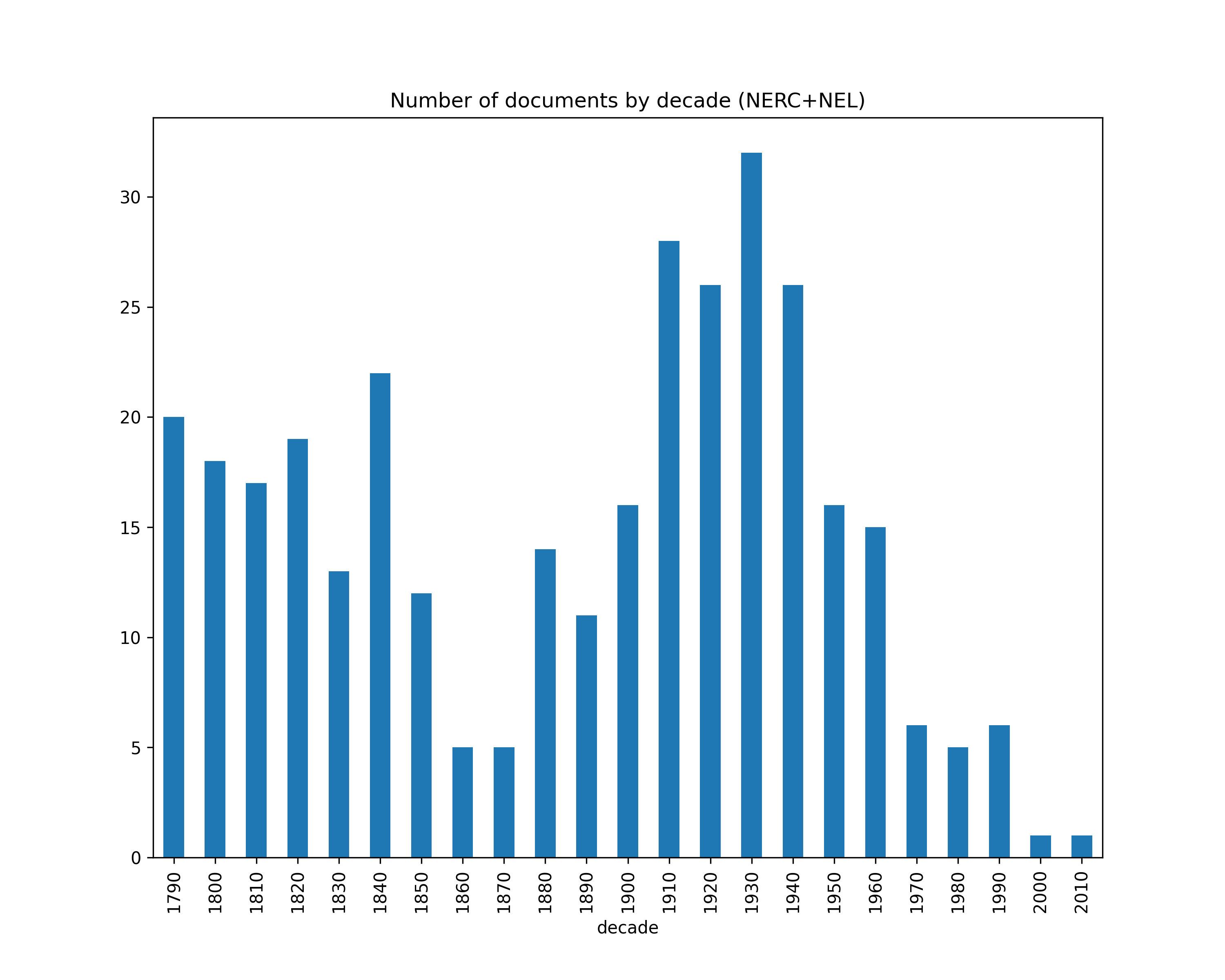
Number of documents by decade
Number of tokens by decade
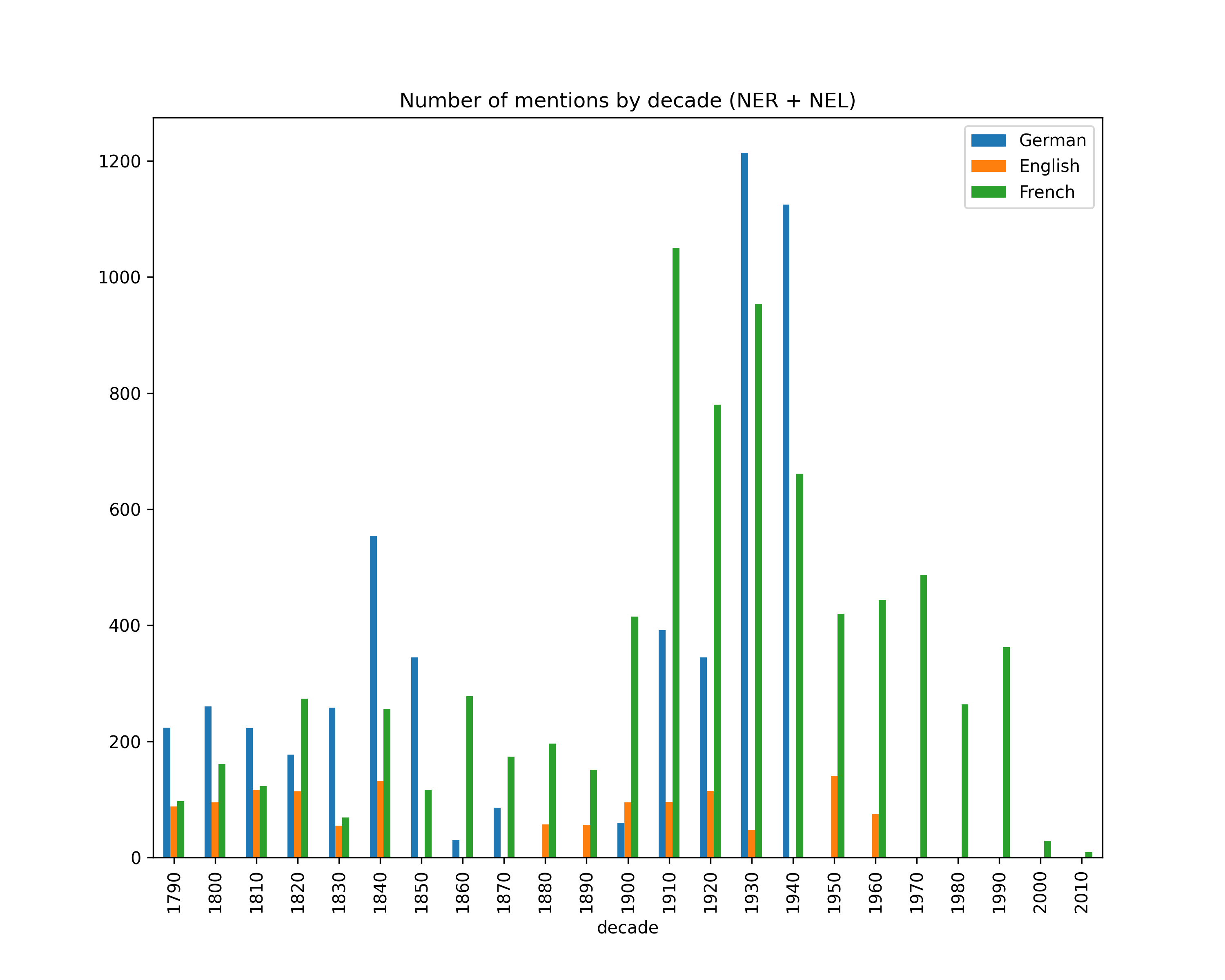
Number of mentions by decade
Number of mentions, broken down by type (coarse)
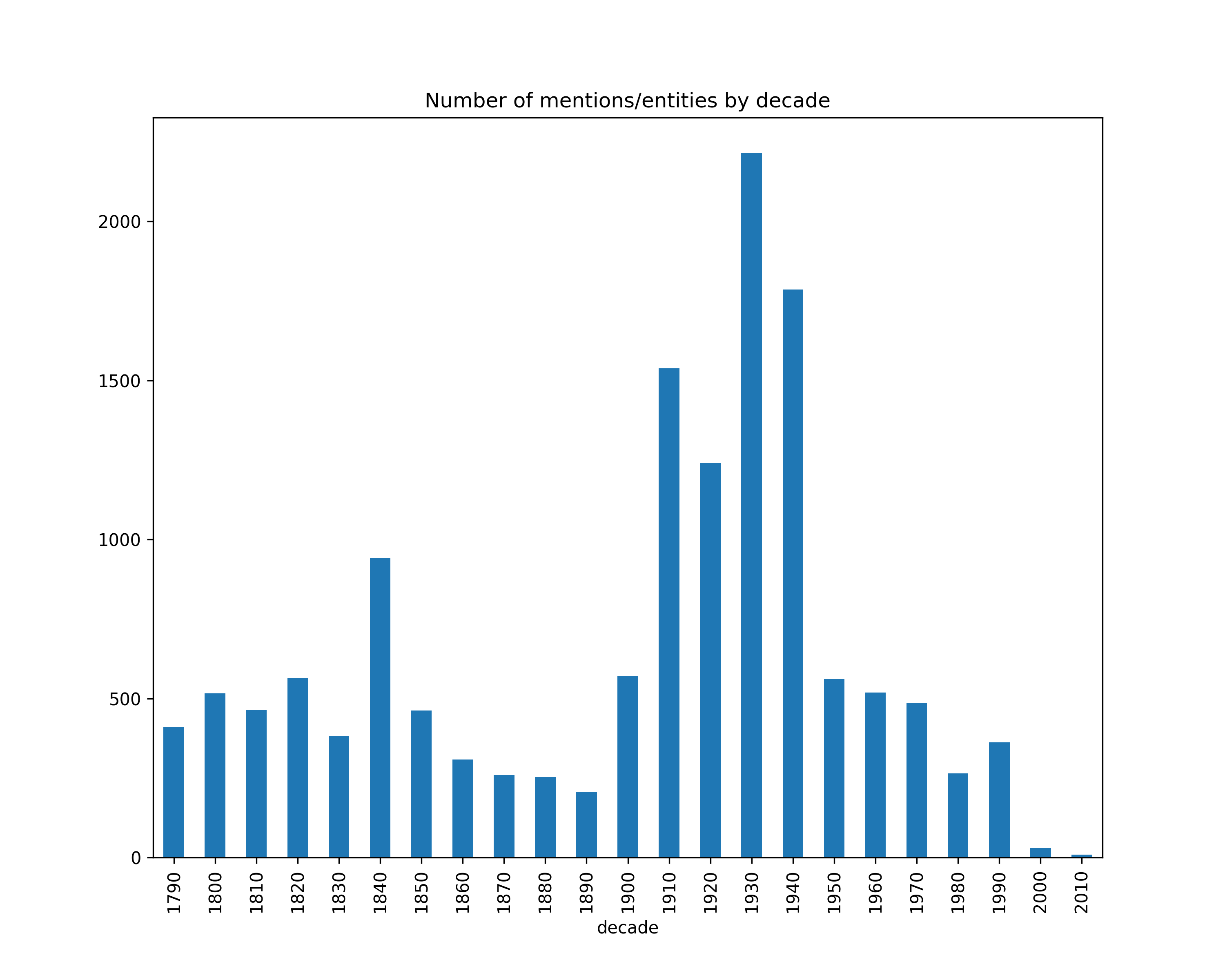
Number of mentions by decade, broken down by type (coarse)
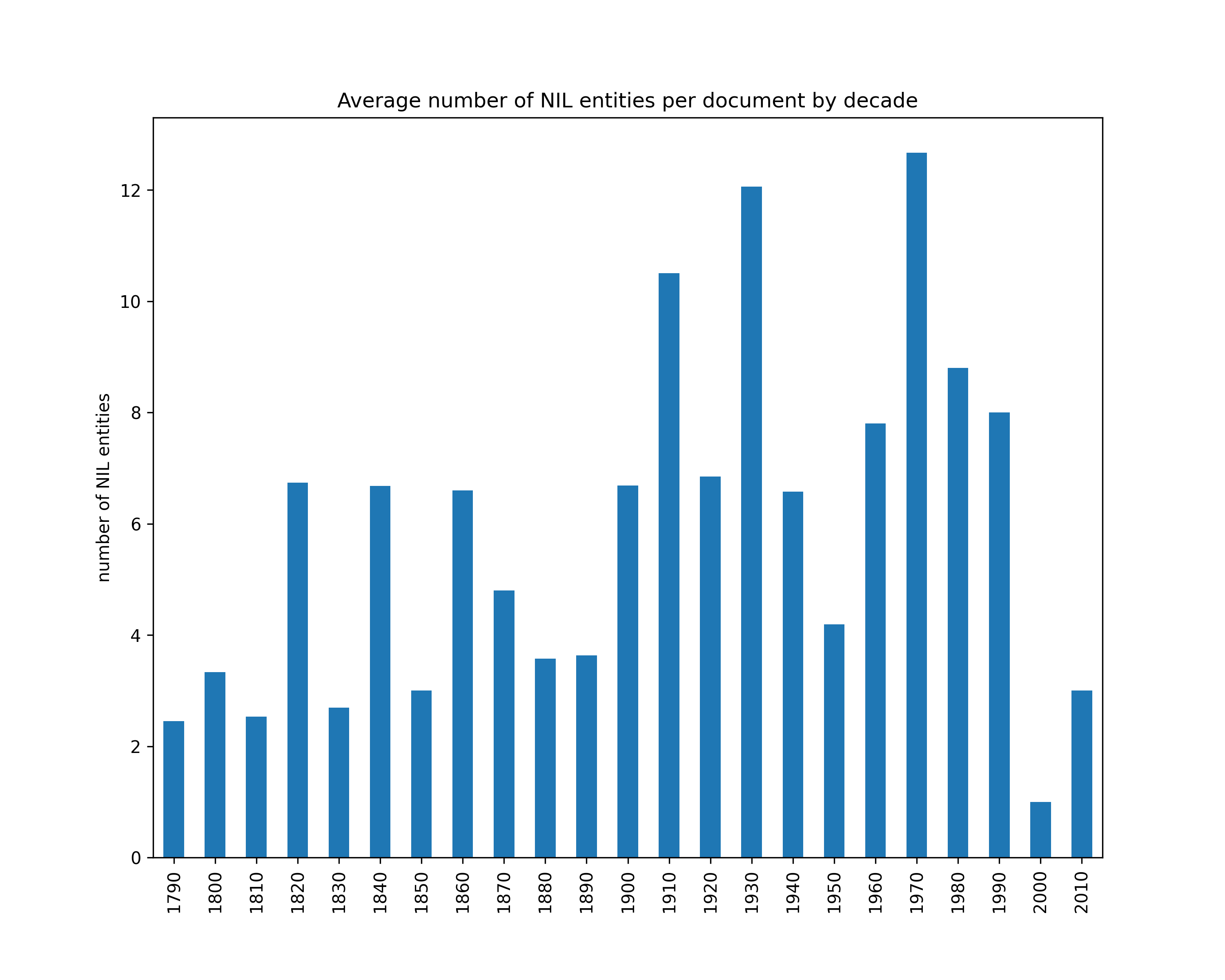
Average number of NIL entities per document
We link mentions against Wikidata. NIL entities are those that do not have a corresponding entry in Wikidata.
NIL entities ratio
Number of NIL entities over the total number of mentions (per decade).
NIL entities by mention type (coarse)

Metonymy