Interfaces for the exploration and analysis of enriched and integrated historical media — To facilitate research on our data, we develop two research-oriented user interfaces: the Impresso web app, a powerful graphical user interface, and the Impresso data lab, developed around a user-oriented API. The design of both interfaces is informed by case studies and associated user needs, including transparency requirements. This to ensure a robust foundation for infrastructure and data sustainability and to establish a central hub for the creation of a research community around our corpus and interfaces.
The Impresso web app for source exploration
The web app builds on the application developed during the first Impresso project and merges traditional functionalities like keyword and faceted search with innovative features for exploring the enriched corpus. Its key functionalities are:
-
Corpus overview: Presenting contextual information on source provenance, data enrichment, and high-level overviews of corpus composition including different types of text (newspapers, typescripts, transcribed speech) and audio recordings.
-
Search and filtering: Enabling advanced operations for enriched media sources across modalities, time, and modalities based on metadata and semantic enrichments.
-
Content retrieval and exploration: Integrating data visualisation, content viewers, and audio players for seamless transitions between close and distant reading.
-
Comparative perspectives: Offering advanced comparative views on research data collections, supporting the discovery of patterns and facilitating content-based similarity ranking and recommendation.
-
Seamless integration: Ensuring smooth integration with the Impresso data lab for efficient research workflows.
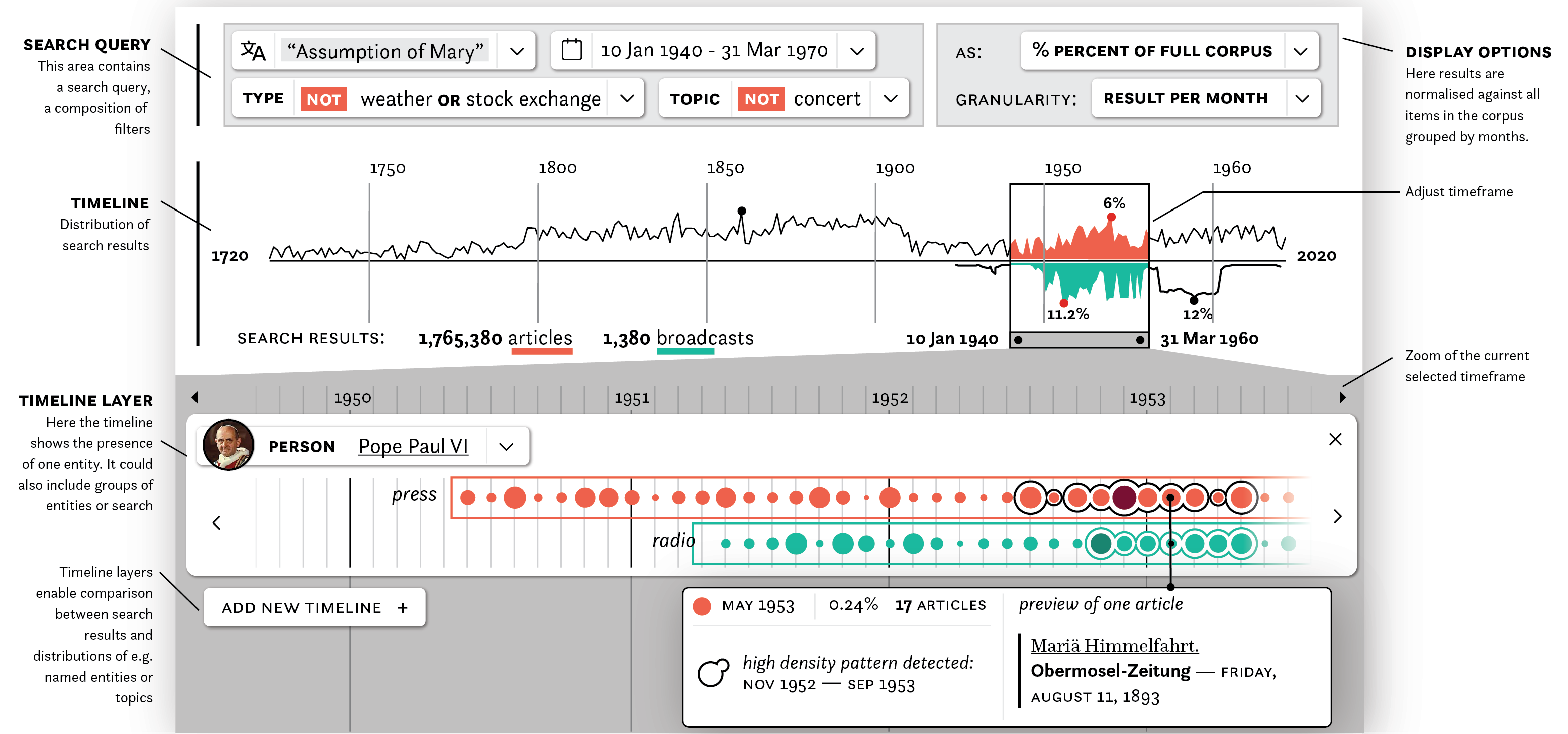
First mockup of a proposed timeline-based interface for interactive exploration.
The Impresso data lab for computational analysis
The Impresso data lab offers access to our corpus, enrichments, and tools by providing a dedicated API that also offers document annotation services. This will constitute a transparent and versatile framework for data-driven comparative analysis of internal and research-specific external documents. Overall, the data lab will offer the following services:
-
API accessibility: Opening the corpus, enrichments, and tools for programmatic exploitation.
-
Dynamic research workflows: Experimenting with modular, dynamic, and personalized research workflows to bridge the gap between digitized collections and data-driven historical research.
-
Annotation service: Enabling the enrichment of user-provided documents by project-based NLP components, supporting e.g. topic models, named entity recognition, keyphrase extraction, and vectorized representations.
-
Enrichment import: Allowing users e.g. to import external enrichments of project documents and empowering researchers to work with self-generated topics in the interface.
The user-oriented API will provide convenience modules for programmatic exploitation of data and enable researchers to process the project’ corpus and enrichments along with other documents and using (external) libraries relevant to their research needs.